De grader av frihet i statistik är de antalet oberoende komponenter i en slumpmässig vektor. Om vektorn har n komponenter och det finns sid linjära ekvationer som relaterar deras komponenter, sedan grad av frihet är n-p.
Konceptet av grader av frihet Det förekommer också i teoretisk mekanik, där de ungefär motsvarar dimensionen i rymden där partikeln rör sig, minus antalet bindningar..
Denna artikel kommer att diskutera begreppet frihetsgrader som tillämpas på statistik, men ett mekaniskt exempel är lättare att visualisera i geometrisk form.
Artikelindex
Beroende på i vilket sammanhang det tillämpas kan sättet att beräkna antalet frihetsgrader variera, men den underliggande idén är alltid densamma: totala dimensioner minus antal begränsningar.
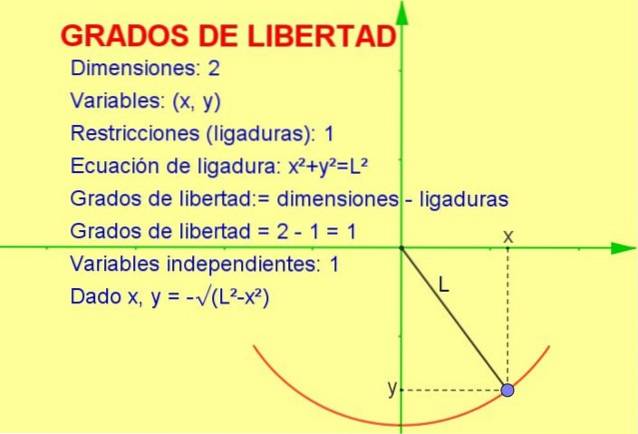
Låt oss överväga en oscillerande partikel bunden till en sträng (en pendel) som rör sig i det vertikala x-y-planet (2 dimensioner). Partikeln tvingas emellertid att röra sig på radiens omkrets lika med ackordets längd.
Eftersom partikeln bara kan röra sig på den kurvan, är antalet grader av frihet är 1. Detta kan ses i figur 1.
Sättet att beräkna antalet frihetsgrader är genom att ta skillnaden mellan antalet dimensioner minus antalet begränsningar:
frihetsgrader: = 2 (dimensioner) - 1 (ligatur) = 1
En annan förklaring som låter oss nå fram till resultatet är följande:
-Vi vet att positionen i två dimensioner representeras av en koordinatpunkt (x, y).
-Men eftersom punkten måste uppfylla ekvationen för omkretsen (xtvå + Ytvå = Ltvå) för ett givet värde av variabeln x bestäms variabeln y av nämnda ekvation eller begränsning.
Således är endast en av variablerna oberoende och systemet har en (1) grad av frihet.
Antag vektorn för att illustrera vad konceptet betyder
x = (x1, xtvå,..., xn)
Vad representerar urvalet av n normalt fördelade slumpmässiga värden. I detta fall den slumpmässiga vektorn x ha n oberoende komponenter och därför sägs det x ha n grader av frihet.
Låt oss nu bygga vektorn r av avfall
r = (x1 -
Var
Så summan
(x1 -
Det är en ekvation som representerar en begränsning (eller bindning) för elementen i vektorn r av resterna, eftersom om n-1-komponenter i vektorn är kända r, begränsningsekvationen bestämmer den okända komponenten.
Därför vektorn r av dimension n med begränsningen:
∑ (xi -
Ha (n - 1) frihetsgrader.
Återigen tillämpas att beräkningen av antalet frihetsgrader är:
frihetsgrader: = n (dimensioner) - 1 (begränsningar) = n-1
Variansen stvå definieras som medelvärdet av kvadraten för avvikelserna (eller resterna) av urvalet av n-data:
stvå = (r•r) / (n-1)
var r är vektorn för resterna r = (x1 -
stvå = ∑ (xi -
I vilket fall som helst bör det noteras att vid beräkning av medelvärdet av resterna delas det av (n-1) och inte av n, eftersom som diskuterats i föregående avsnitt, antalet frihetsgrader för vektor r är (n-1).
Om för beräkningen av variansen dividerades med n istället för (n-1) skulle resultatet ha en bias som är mycket signifikant för värdena på n under 50.
I litteraturen visas variansformeln också med delaren n istället för (n-1), när det gäller variationen hos en population.
Men uppsättningen av den slumpmässiga variabeln för resterna, representerad av vektorn r, Även om den har dimension n har den bara (n-1) frihetsgrader. Men om antalet data är tillräckligt stort (n> 500) konvergerar båda formlerna till samma resultat.
Miniräknare och kalkylark ger båda versionerna av variansen och standardavvikelsen (som är kvadratroten av variansen).
Vår rekommendation, med tanke på analysen som presenteras här, är att alltid välja version med (n-1) varje gång det krävs att beräkna varians eller standardavvikelse för att undvika partiska resultat..
Vissa sannolikhetsfördelningar i kontinuerlig slumpmässig variabel beror på en parameter som kallas grad av frihet, är fallet med Chi-kvadratfördelningen (χtvå).
Namnet på denna parameter kommer exakt från frihetsgraderna för den underliggande slumpmässiga vektorn som denna fördelning gäller.
Antag att vi har gpopulationer, från vilka prover av storlek n tas:
X1 = (x11, x1två,... X1n)
X2 = (x21, x2två,... X2n)
... .
Xj = (xj1, xjtvå,... Xjn)
... .
Xg = (xg1, xgtvå,... Xgn)
En befolkning j vad har genomsnittet
Den standardiserade eller normaliserade variabeln zji är definierad som:
zji = (xji -
Och vektorn Zj definieras så här:
Zj = (zj1, zjtvå,..., zji,..., zjn) och följer den standardiserade normalfördelningen N (0,1).
Så variabeln:
F = ((z11 ^ 2 + z21^ 2 +…. + zg1^ 2),…., (Z1n^ 2 + z2n^ 2 +…. + zgn^ 2))
följ distributionen χtvå(g) kallade chi fyrkantig fördelning med grad av frihet g.
När du vill testa hypoteser baserade på en viss uppsättning slumpmässiga data måste du känna till antal frihetsgrader g för att kunna tillämpa Chi kvadrat testet.
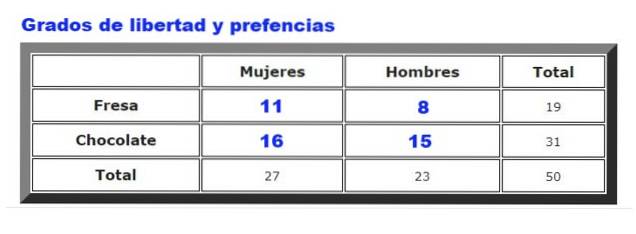
Som ett exempel kommer de uppgifter som samlats in om choklad- eller jordgubbglassens preferenser bland män och kvinnor i en viss glassbar. Frekvensen med vilken män och kvinnor väljer jordgubbe eller choklad sammanfattas i figur 2.
Först beräknas tabellen över förväntade frekvenser, som bereds genom att multiplicera totalt antal rader för honom totalt kolumner, delat med totala data. Resultatet visas i följande bild:

Sedan fortsätter vi med att beräkna Chi-kvadraten (från data) med följande formel:
χtvå = ∑ (Feller - Foch)två / Foch
Där Feller är de observerade frekvenserna (Figur 2) och Foch är de förväntade frekvenserna (figur 3). Summationen går över alla rader och kolumner, vilket i vårt exempel ger fyra termer.
Efter att ha gjort operationerna får du:
χtvå = 0,2043.
Nu är det nödvändigt att jämföra med den teoretiska Chi-kvadraten, som beror på antal frihetsgrader g.
I vårt fall bestäms detta antal enligt följande:
g = (# rader - 1) (# kolumner - 1) = (2 - 1) (2 - 1) = 1 * 1 = 1.
Det visar sig att antalet frihetsgrader g i detta exempel är 1.
Om du vill kontrollera eller avvisa nollhypotesen (H0: det finns ingen korrelation mellan SMAK och KÖN) med en signifikansnivå på 1% beräknas det teoretiska Chi-kvadratvärdet med frihetsgraden g = 1.
Värdet söks som gör den ackumulerade frekvensen (1 - 0.01) = 0.99, det vill säga 99%. Detta värde (som kan erhållas från tabellerna) är 6.636.
Eftersom den teoretiska Chi överstiger den beräknade, verifieras nollhypotesen.
Det vill säga med de insamlade uppgifterna, Inte observerat förhållandet mellan variablerna TASTE och KÖN.


Ingen har kommenterat den här artikeln än.