
De kumulativa frekvensen är summan av de absoluta frekvenserna f, från den lägsta till den som motsvarar ett visst värde för variabeln. I sin tur är den absoluta frekvensen det antal gånger en observation visas i datamängden.
Uppenbarligen måste studievariabeln vara sorterbar. Och eftersom den ackumulerade frekvensen erhålls genom att lägga till de absoluta frekvenserna, visar det sig att den ackumulerade frekvensen fram till den sista datan måste sammanfalla med den totala frekvensen. Annars finns det ett fel i beräkningarna.

Vanligtvis betecknas den kumulativa frekvensen som Fi (eller ibland ni), för att skilja den från den absoluta frekvensen fi och det är viktigt att lägga till en kolumn för den i tabellen som data är organiserade med, så kallad frekvenstabell.
Detta underlättar bland annat att hålla reda på hur mycket data som räknades upp till en viss observation..
A Fi det är också känt som absolut kumulativ frekvens. Om dividerat med den totala informationen har vi relativ kumulativ frekvens, vars slutliga summa måste vara lika med 1.
Artikelindex
Den kumulativa frekvensen för ett givet värde för variabel Xi är summan av de absoluta frekvenserna f för alla värden som är mindre än eller lika med det:
Fi = f1 + Ftvå + F3 +... fi
Genom att lägga till alla absoluta frekvenser erhålls det totala antalet data N, det vill säga:
F1 + Ftvå + F3 +.... + Fn = N
Den tidigare operationen skrivs på ett sammanfattat sätt med hjälp av summeringssymbolen:
∑ Fi = N
Följande frekvenser kan också ackumuleras:
-Relativ frekvens: erhålls genom att dela den absoluta frekvensen fi mellan de totala uppgifterna N:
Fr = fi / N
Om de relativa frekvenserna från den lägsta till den som motsvarar en viss observation läggs till har vi kumulativ relativ frekvens. Det sista värdet måste vara lika med 1.
-Procentuell kumulativ relativ frekvens: den ackumulerade relativa frekvensen multipliceras med 100%.
F% = (fi / N) x 100%
Dessa frekvenser är användbara för att beskriva beteendet hos data, till exempel när man hittar mått på central tendens.
För att erhålla den ackumulerade frekvensen är det nödvändigt att beställa data och organisera dem i en frekvenstabell. Förfarandet illustreras i följande praktiska situation:
-I en webbutik som säljer mobiltelefoner visade försäljningsrekordet för ett visst varumärke för mars månad följande värden per dag:
1; två; 1; 3; 0; 1; 0; två; 4; två; 1; 0; 3; 3; 0; 1; två; 4; 1; två; 3; två; 3; 1; två; 4; två; 1; 5; 5; 3
Variabeln är antal sålda telefoner per dag och det är kvantitativt. Informationen som presenteras på detta sätt är inte så lätt att tolka, till exempel kan butikens ägare vara intresserade av att veta om det finns någon trend, till exempel veckodagar då försäljningen av det varumärket är högre..
Information som denna och mer kan erhållas genom att presentera data på ett ordnat sätt och specificera frekvenserna..
För att beräkna den kumulativa frekvensen beställs först data:
0; 0; 0; 0; 1; 1; 1; 1; 1; 1; 1; 1; två; två; två; två; två; två; två; två; 3; 3; 3; 3; 3; 3; 4; 4; 4; 5; 5
Sedan byggs en tabell med följande information:
-Den första kolumnen till vänster med antalet sålda telefoner, mellan 0 och 5 och i ökande ordning.
-Andra kolumnen: absolut frekvens, vilket är antalet dagar som 0 telefoner, 1 telefon, 2 telefoner och så vidare såldes.
-Tredje kolumnen: den ackumulerade frekvensen, som består av summan av den tidigare frekvensen plus frekvensen för de data som ska beaktas.
Den här kolumnen börjar med de första uppgifterna i kolumnen med absolut frekvens, i detta fall är den 0. För nästa värde, lägg till detta med det föregående. Det fortsätter så här tills det når de sista data för den ackumulerade frekvensen, som måste sammanfalla med den totala datan.
Följande tabell visar variabeln "antal sålda telefoner på en dag", dess absoluta frekvens och den detaljerade beräkningen av den ackumulerade frekvensen.
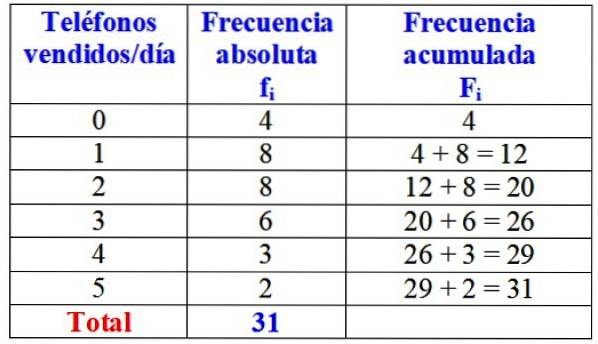
Vid en första anblick kan man säga att av varumärket ifråga säljs en eller två telefoner nästan alltid om dagen, eftersom den högsta absoluta frekvensen är 8 dagar, vilket motsvarar dessa variabelvärden. Endast under fyra dagar i månaden sålde de inte en enda telefon.
Som nämnts är tabellen lättare att undersöka än de individuella uppgifter som ursprungligen samlats in.
En kumulativ frekvensfördelning är en tabell som visar de absoluta frekvenserna, de kumulativa frekvenserna, de kumulativa relativa frekvenserna och de kumulativa procentuella frekvenserna..
Även om det finns fördelen med att organisera data i en tabell som den föregående, om antalet data är mycket stort, kanske det inte räcker att organisera dem som visas ovan, för om det finns många frekvenser blir det fortfarande svårt att tolka.
Problemet kan åtgärdas genom att bygga en frekvensfördelning med intervall, ett användbart förfarande när variabeln tar ett stort antal värden eller om det är en kontinuerlig variabel.
Här grupperas värdena i intervaller med lika amplitud, kallade klass. Klasserna kännetecknas av att de har:
-Klassgräns: är de extrema värdena för varje intervall, det finns två, den övre gränsen och den nedre gränsen. I allmänhet hör den övre gränsen inte till intervallet utan till nästa, medan den nedre gränsen tillhör.
-Klassmärke: är mittpunkten för varje intervall och tas som det representativa värdet av det.
-Klassbredd: Det beräknas genom att subtrahera värdet på de största och minsta data (intervall) och dividera med antalet klasser:
Klassbredd = Område / antal klasser
Utarbetningen av frekvensfördelningen beskrivs nedan..
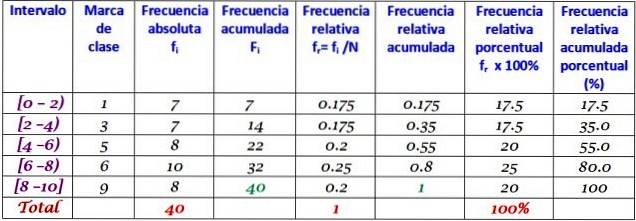
Denna datamängd motsvarar 40 poäng i ett matematikprov, på en skala från 0 till 10:
0; 0; 0; 1; 1; 1; 1; två; två; två; 3; 3; 3; 3; 4; 4; 4; 4; 5; 5; 5; 5; 6; 6; 6; 6; 7; 7; 7; 7; 7; 7; 8; 8; 8; 9; 9; 9; 10; 10.
En frekvensfördelning kan göras med ett visst antal klasser, till exempel 5 klasser. Man bör komma ihåg att data är inte lätt att tolka när man använder många klasser och känslan av att genomföra gruppering går förlorad.
Och om de tvärtom är grupperade i mycket få, späds informationen och en del av den går förlorad. Allt beror på mängden data du har.
I det här exemplet är det en bra idé att ha två poäng i varje intervall, eftersom det finns 10 poäng och 5 klasser skapas. Området är subtraktionen mellan högsta och lägsta betyg, klassbredden är:
Klassbredd = (10-0) / 5 = 2
Intervallen är stängda till vänster och öppna till höger (förutom den sista), vilket symboliseras av parentes respektive parentes. De har alla samma bredd, men det är inte obligatoriskt, men det är oftast.
Varje intervall innehåller en viss mängd element eller absolut frekvens, och i nästa kolumn är den ackumulerade frekvensen, i vilken summan bärs. Tabellen visar också den relativa frekvensen fr (absolut frekvens mellan det totala antalet data) och den relativa procentuella frekvensen fr × 100%.
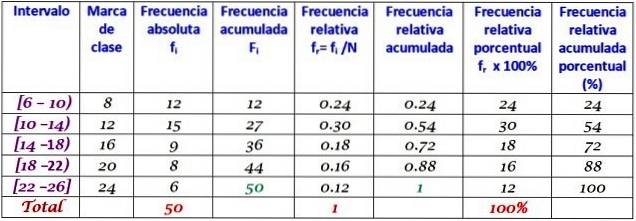
Ett företag ringde dagligen till sina kunder under årets två första månader. Uppgifterna är som följer:
6, 12, 7, 15, 13, 18, 20, 25, 12, 10, 8, 13, 15, 6, 9, 18, 20, 24, 12, 7, 10, 11, 13, 9, 12, 15, 18, 20, 13, 17, 23, 25, 14, 18, 6, 14, 16, 9, 6, 10, 12, 20, 13, 17, 14, 26, 7, 12, 24, 7
Gruppera i 5 klasser och bygg tabellen med frekvensfördelningen.
Klassbredden är:
(26-6) / 5 = 4
Försök ta reda på det innan du ser svaret.


Ingen har kommenterat den här artikeln än.