De mått på variation, Även kallade mått på spridning, de är statistiska indikatorer som indikerar hur nära eller långt data ligger från dess aritmetiska medelvärde. Om data ligger nära medelvärdet är fördelningen koncentrerad och om de är långt borta är det en gles fördelning..
Det finns många mått på variation, bland de mest kända är:
Dessa åtgärder kompletterar måtten på den centrala tendensen och är nödvändiga för att förstå fördelningen av de erhållna uppgifterna och extrahera från dem så mycket information som möjligt..
Räckvidd eller spann mäter bredden på en datamängd. För att bestämma dess värde, skillnaden mellan data med det högsta värdet xmax och den med det lägsta värdet xmin:
R = xmax - xmin
Om data inte är lösa utan grupperas efter intervall beräknas intervallet av skillnaden mellan den övre gränsen för det sista intervallet och den nedre gränsen för det första intervallet.
När intervallet är ett litet värde betyder det att all information ligger ganska nära varandra, men ett stort intervall indikerar att det finns mycket variation. Det är tydligt att, förutom den övre och nedre gränsen för data, tar intervallet inte hänsyn till värdena mellan dem, så det rekommenderas inte att använda det när antalet data är stort.
Det är dock ett omedelbart mått att beräkna och har samma enheter av data, så det är lätt att tolka.
Nedan är listan med antal mål under helgen, i fotbollsligorna i nio länder:
40, 32, 35, 36, 37, 31, 37, 29, 39
Detta är en icke-grupperad datamängd. För att hitta intervallet fortsätter vi med att beställa dem från lägsta till högsta:
29, 31, 32, 35, 36, 37, 37, 39, 40
Data med det högsta värdet är 40 mål och den med det lägsta värdet är 29 mål, därför är intervallet:
R = 40−29 = 11 mål.
Man kan betrakta att intervallet är litet jämfört med minimivärdedata, vilket är 29 mål, så det kan antas att data inte har stor variation.
Detta mått på variation beräknas genom medelvärdet av de absoluta värdena för avvikelserna i förhållande till medelvärdet.. Betecknar den genomsnittliga avvikelsen som DM, För icke-grupperade data beräknas medelavvikelsen enligt följande formel:
Där n är antalet tillgängliga data, xi representerar varje data och x̄ är medelvärdet, vilket bestäms genom att lägga till all data och dela med n:
Medelavvikelsen gör det möjligt att i genomsnitt veta hur många enheter data avviker från det aritmetiska medelvärdet och har fördelen att ha samma enheter som de data vi arbetar med.
Baserat på uppgifterna från intervallet är antalet mål som görs:
40, 32, 35, 36, 37, 31, 37, 29, 39
Om du vill hitta medelavvikelsen DM Från dessa data är det nödvändigt att först beräkna det aritmetiska medelvärdet x̄:

Och nu när värdet på x̄ är känt fortsätter vi med att hitta medelavvikelsen DM:
= 2,99 ≈ 3 mål
Därför kan det konstateras att data i genomsnitt ligger cirka 3 mål från genomsnittet, vilket är 35 mål, och som nämnts är det ett mycket mer exakt mått än intervallet..
Medelavvikelsen är ett mycket finare mått på variationer än intervallet, men eftersom det beräknas genom det absoluta värdet av skillnaderna mellan varje data och medelvärdet, erbjuder det inte större mångsidighet ur en algebraisk synvinkel..
Av denna anledning föredras variansen, vilket motsvarar genomsnittet av den kvadratiska skillnaden för varje data med medelvärdet och beräknas med formeln:
I detta uttryck, stvå betecknar variansen, och som alltid xi representerar var och en av data, x̄ är medelvärdet och n är den totala datan.
När du arbetar med ett urval istället för populationen föredras det att beräkna variansen så här:
I vilket fall som helst kännetecknas variansen av att alltid vara en positiv kvantitet, men eftersom det är medelvärdet av de kvadratiska skillnaderna är det viktigt att notera att den inte har samma enheter som data..
För att beräkna variansen av data i exemplen på intervall och medelavvikelse fortsätter vi med att ersätta motsvarande värden och utföra den angivna summeringen. I det här fallet väljer vi att dela med n-1:

= 13,86
Variansen har inte samma enhet som variabeln som studeras, till exempel om data kommer i meter, resulterar variansen i kvadratmeter. Eller i målexemplet skulle det vara i mål i kvadrat, vilket inte är vettigt.
Därför definieras standardavvikelsen, även kallad typisk avvikelse, som kvadratroten av variansen:
s = √stvå
På detta sätt erhålls ett mått på datavariabilitet i samma enheter som dessa, och ju lägre värdet på s, desto mer grupperad är data kring medelvärdet..
Både variansen och standardavvikelsen är måtten på variabilitet som ska väljas när det aritmetiska medelvärdet är det mått på den centrala tendensen som bäst beskriver datas beteende..
Och det är att standardavvikelsen har en viktig egenskap, känd som Chebyshevs sats: minst 75% av observationerna ligger inom det intervall som definieras av x̄ ± 2s. Med andra ord är 75% av uppgifterna högst två sekunder från medelvärdet..
På samma sätt är minst 89% av värdena på ett avstånd av 3s från medelvärdet, en procentsats som kan expanderas, så länge det finns mycket data tillgängligt och de följer en normalfördelning..
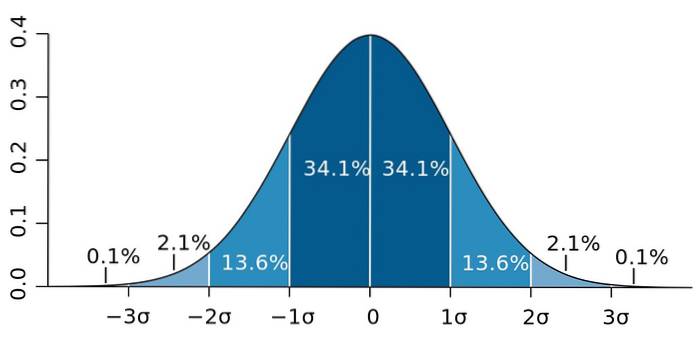
Figur 2. - Om data följer en normalfördelning ligger 95,4 av dem inom två standardavvikelser på båda sidor om medelvärdet. Källa: Wikimedia Commons.
Standardavvikelsen för de data som presenteras i föregående exempel är:
s = √stvå = √13,86 = 3,7 ≈ 4 mål



Ingen har kommenterat den här artikeln än.