De hypergeometrisk fördelning är en diskret statistisk funktion, lämplig för att beräkna sannolikheten i randomiserade experiment med två möjliga resultat. Villkoret som krävs för att tillämpa det är att de är små populationer, där extraktionerna inte ersätts och sannolikheten inte är konstant..
Därför, när en del av befolkningen väljs för att känna till resultatet (sant eller falskt) av en viss egenskap, kan samma element inte väljas igen..

Visst är nästa utvalda element således mer sannolikt att uppnå ett verkligt resultat om det tidigare elementet hade ett negativt resultat. Detta innebär att sannolikheten varierar när element extraheras från provet..
Huvudapplikationerna för den hypergeometriska fördelningen är: kvalitetskontroll i processer med liten befolkning och beräkning av sannolikheter i hasardspel.
När det gäller den matematiska funktionen som definierar den hypergeometriska fördelningen består den av tre parametrar, vilka är:
- Antal befolkningselement (N)
- Provstorlek (m)
- Antal händelser i hela befolkningen med ett gynnsamt (eller ogynnsamt) resultat av den studerade egenskapen (n).
Artikelindex
Formeln för den hypergeometriska fördelningen ger sannolikheten P om vad x gynnsamma fall av en viss egenskap förekommer. Sättet att skriva det matematiskt baserat på de kombinerande siffrorna är:
I ovanstående uttryck N, n Y m är parametrar och x själva variabeln.
-Den totala befolkningen är N.
-Antal positiva resultat för en viss binär karakteristik med avseende på den totala befolkningen är n.
-Antalet provvaror är m.
I detta fall, X är en slumpmässig variabel som tar värdet x Y P (x) anger sannolikheten för förekomst av x gynnsamma fall av den studerade egenskapen.
Andra statistiska variabler för den hypergeometriska fördelningen är:
- Halv μ = m * n / N
- Variation σ ^ 2 = m * (n / N) * (1-n / N) * (N-m) / (N-1)
- Typisk avvikelse σ vilket är kvadratroten av variansen.
För att komma fram till modellen för den hypergeometriska fördelningen, utgår vi från sannolikheten att få x gynnsamma fall i en provstorlek m. Nämnda exempel innehåller element som överensstämmer med egenskapen som studeras och element som inte gör det.
Kom ihåg det n representerar antalet gynnsamma fall i den totala befolkningen i N element. Då beräknades sannolikheten så här:
P (x) = (# sätt att få x # misslyckade sätt) / (totalt antal sätt att välja)
Genom att uttrycka ovanstående i form av kombinatoriska siffror kommer vi fram till följande sannolikhetsfördelningsmodell:
De är som följer:
- Provet måste alltid vara litet, även om populationen är stor.
- Elementen i provet extraheras en efter en utan att integrera dem tillbaka i populationen.
- Egenskapen som ska studeras är binär, det vill säga det kan bara ta två värden: 1 eller 0, Nåväl vissa eller falsk.
I varje elementextraktionssteg ändras sannolikheten beroende på tidigare resultat.
En annan egenskap hos den hypergeometriska fördelningen är att den kan approximeras med binomialfördelningen, betecknad som Bi, så länge som befolkningen N är stor och minst tio gånger större än provet m. I det här fallet skulle det se ut så här:
P (N, n, m; x) = Bi (m, n / N, x)
Gäller så länge N är stor och N> 10m
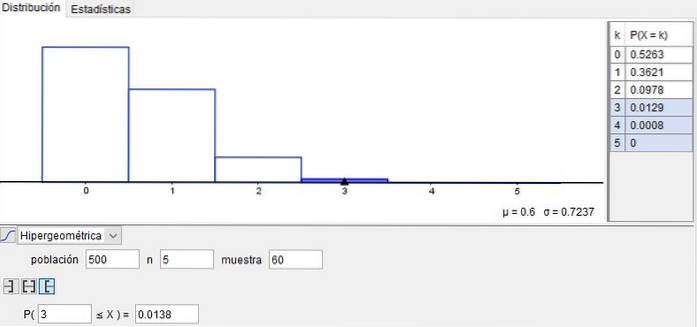
Anta att en maskin som producerar skruvar och de ackumulerade uppgifterna indikerar att 1% kommer ut med defekter. I en låda med N = 500 skruvar kommer antalet defekter att vara:
n = 500 * 1/100 = 5
Antag att från den rutan (det vill säga från den populationen) tar vi ett urval av m = 60 bultar.
Sannolikheten att ingen skruv (x = 0) i provet är defekt är 52,63%. Detta resultat uppnås med hjälp av den hypergeometriska fördelningsfunktionen:
P (500, 5, 60, 0) = 0,5263
Sannolikheten att x = 3 skruvar i provet är defekta är: P (500, 5, 60, 3) = 0,0129.
Å andra sidan är sannolikheten att x = 4 skruvar av sextio av provet är defekta: P (500, 5, 60; 4) = 0,0008.
Slutligen är sannolikheten att x = 5 skruvar i det provet är defekta: P (500, 5, 60; 5) = 0.
Men om du vill veta sannolikheten att det i det provet finns mer än tre defekta skruvar, måste du få den kumulativa sannolikheten och lägga till:
P (3) + P (4) + P (5) = 0,0129 + 0,0008 + 0 = 0,0137.
Detta exempel illustreras i figur 2, erhållen med användning av GeoGebra en gratis programvara som ofta används i skolor, institut och universitet.
En spansk kortlek har 40 kort, varav 10 har guld och de återstående 30 inte. Anta att sju kort dras slumpmässigt från det däcket, som inte återinförs i däcket.
Om X är antalet guld som finns i de 7 utdragna korten, ges sannolikheten att det kommer att finnas x guld i en 7-kortdragning av den hypergeometriska fördelningen P (40,10,7; x).
Låt oss se detta så här: för att beräkna sannolikheten för att ha 4 guld i en 7-kortsdragning använder vi formeln för den hypergeometriska fördelningen med följande värden:

Och resultatet är: 4,57% sannolikhet.
Men om du vill veta sannolikheten för att få fler än fyra kort måste du lägga till:
P (4) + P (5) + P (6) + P (7) = 5,20%
Följande övningsuppsättning är avsedd att illustrera och assimilera de begrepp som presenteras i den här artikeln. Det är viktigt att läsaren försöker lösa dem på egen hand innan han tittar på lösningen.
En kondomfabrik har funnit att av 1000 kondomer som produceras av en viss maskin kommer 5 ut defekta. För kvalitetskontroll tas 100 kondomer slumpmässigt och partiet avvisas om det finns minst en eller flera defekter. Svar:
a) Vad är möjligheten att många 100 kommer att kasseras?
b) Är detta kvalitetskontrollkriterium effektivt??
I det här fallet kommer mycket stora kombinatoriska siffror att visas. Beräkning är svår om inte ett lämpligt programvarupaket finns tillgängligt.
Men eftersom det är en stor population och urvalet är tio gånger mindre än den totala populationen, är det möjligt att använda approximationen av den hypergeometriska fördelningen med binomialfördelningen:
P (1000,5,100; x) = Bi (100, 5/1000, x) = Bi (100, 0,005, x) = C (100, x) * 0,005 ^ x (1-0,005) ^ (100-x)
I ovanstående uttryck C (100, x) är ett kombinationsnummer. Då beräknas sannolikheten för att det finns mer än en defekt så här:
P (x> = 1) = 1 - Bi (0) = 1- 0,6058 = 0,3942
Det är en utmärkt approximation, om den jämförs med det värde som erhålls genom att använda den hypergeometriska fördelningen: 0,4102
Det kan sägas att med 40% sannolikhet bör en sats på 100 profylaktiska medel kastas, vilket inte är särskilt effektivt..
Men eftersom vi är lite mindre krävande i kvalitetskontrollprocessen och vi skulle bara kasta satsen om 100 om det finns två eller flera brister, skulle sannolikheten för att kasta satsen sjunka till bara 8%..
En plastpluggmaskin fungerar på ett sådant sätt att en av 10 stycken blir en deformerad. I ett prov på 5 stycken, hur troligt är det att bara en bit är defekt?.
Befolkning: N = 10
Antal n defekter för varje N: n = 1
Provstorlek: m = 5
P (10, 1, 5; 1) = C (1,1) * C (9,4) / C (10,5) = 1 * 126/252 = 0,5
Därför är det en sannolikhet på 50% att i ett prov på 5 kommer en ledtråd att bli deformerad.
Vid ett möte med unga gymnasieelever finns det 7 damer och 6 herrar. Bland flickorna studerar 4 humaniora och 3 vetenskap. I pojkegruppen studerar 1 humaniora och 5 vetenskap. Beräkna följande:
a) Att välja tre tjejer slumpmässigt: vad är sannolikheten för att de alla studerar humaniora?.
b) Om tre deltagare till vänskapsmötet väljs slumpmässigt: Vad är möjligheten att tre av dem, oavsett kön, studerar vetenskap alla tre, eller humaniora också alla tre?.
c) Välj nu två vänner slumpmässigt och ring x till den slumpmässiga variabeln "antal av dem som studerar humaniora". Bestäm medelvärdet eller det förväntade värdet mellan de två valda x och variansen σ ^ 2.
Befolkningen är det totala antalet flickor: N = 7. De som studerar humaniora är n = 4 av summan. Det slumpmässiga urvalet av tjejer blir m = 3.
I det här fallet ges sannolikheten att alla tre är humanistiska studenter av den hypergeometriska funktionen:
P (N = 7, n = 4, m = 3, x = 3) = C (4, 3) C (3, 0) / C (7, 3) = 0,1143
Det finns alltså en sannolikhet på 11,4% att tre tjejer som valts slumpmässigt kommer att studera humaniora..
Värdena som ska användas nu är:
-Befolkning: N = 14
-Mängden som studerar bokstäver är: n = 6 och
-Provstorlek: m = 3.
-Antal vänner som studerar humaniora: x
Enligt detta betyder x = 3 att alla tre studerar humaniora, men x = 0 betyder att ingen studerar humaniora. Sannolikheten att alla tre studerar samma ges av summan:
P (14, 6, 3, x = 0) + P (14, 6, 3, x = 3) = 0,0560 + 0,1539 = 0,2099
Sedan har vi 21% sannolikhet att tre mötesdeltagare, slumpmässigt valda, kommer att studera samma sak.
Här har vi följande värden:
N = 14 totala vänpopulationen, n = 6 totalt antal i den befolkning som studerar humaniora, urvalsstorleken är m = 2.
Hopp är:
E (x) = m * (n / N) = 2 * (6/14) = 0,8572
Och variansen:
σ (x) ^ 2 = m * (n / N) * (1-n / N) * (Nm) / (N-1) = 2 * (6/14) * (1-6 / 14) * (14-2) / (14 -1) =
= 2 * (6/14) * (1-6 / 14) * (14-2) / (14-1) = 2 * (3/7) * (1-3 / 7) * (12) / (13 ) = 0,4521

Ingen har kommenterat den här artikeln än.