De slumpmässigt urval det är sättet att välja ett statistiskt representativt urval från en viss population. En del av principen att varje element i provet ska ha samma sannolikhet att väljas.
En dragning är ett exempel på slumpmässigt urval, där varje medlem av den deltagande befolkningen tilldelas ett nummer. För att välja de siffror som motsvarar lotteripriserna (provet) används en slumpmässig teknik, till exempel extrahera de nummer som spelades in på identiska kort från en brevlåda.
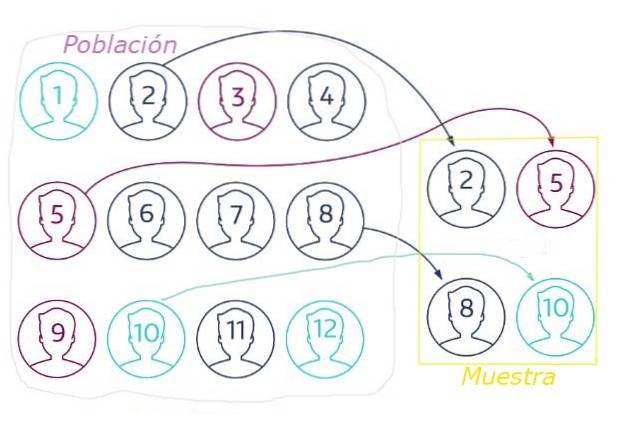
I slumpmässigt urval är det viktigt att välja urvalsstorleken korrekt, eftersom ett icke-representativt urval av befolkningen kan leda till felaktiga slutsatser på grund av statistiska fluktuationer..
Artikelindex
Det finns formler för att bestämma rätt storlek på ett prov. Den viktigaste faktorn att tänka på är om befolkningsstorleken är känd eller inte. Låt oss titta på formlerna för att bestämma provstorleken:
När populationsstorleken N är okänd är det möjligt att välja ett urval av adekvat storlek n för att avgöra om en viss hypotes är sant eller falskt.
För detta används följande formel:
n = (Ztvå p q) / (Etvå)
Var:
-p är sannolikheten för att hypotesen är sant.
-q är sannolikheten att det inte är det, därför är q = 1 - p.
-E är den relativa felmarginalen, till exempel har ett fel på 5% en marginal E = 0,05.
-Z har att göra med den grad av förtroende som studien kräver.
I en standardiserad (eller normaliserad) normalfördelning har en konfidensnivå på 90% Z = 1.645, eftersom sannolikheten att resultatet är mellan -1.645σ och + 1.645σ är 90%, där σ är standardavvikelsen.
1.- 50% konfidensnivå motsvarar Z = 0,675.
2.- 68,3% konfidensnivå motsvarar Z = 1.
3.- 90% konfidensnivå motsvarar Z = 1 645.
4.- 95% konfidensnivå motsvarar Z = 1,96
5.- 95,5% konfidensnivå motsvarar Z = 2.
6.- 99,7% konfidensnivå motsvarar Z = 3.
Ett exempel där denna formel kan tillämpas skulle vara i en studie för att bestämma den genomsnittliga vikten av småsten på en strand.
Det är uppenbart att det inte är möjligt att studera och väga alla småsten på stranden, så det är tillrådligt att extrahera ett prov så slumpmässigt som möjligt och med lämpligt antal element..

När antalet N av element som utgör en viss population (eller universum) är känt, om du vill välja ett statistiskt signifikant urval av storlek n genom enkel slumpmässig sampling, är detta formeln:
n = (Ztvåp q N) / (N Etvå + Ztvåp q)
Var:
-Z är koefficienten associerad med konfidensnivån.
-p är sannolikheten för hypotesens framgång.
-q är sannolikheten för misslyckande i hypotesen, p + q = 1.
-N är storleken på den totala befolkningen.
-E är det relativa felet i studieresultatet.
Metoden för att extrahera proverna beror mycket på vilken typ av studie som behöver göras. Därför har slumpmässigt urval ett oändligt antal applikationer:
I telefonundersökningar väljs till exempel de personer som ska konsulteras med hjälp av en slumptalsgenerator, som är tillämplig på regionen som studeras..
Om du vill tillämpa ett frågeformulär på de anställda i ett stort företag kan du tillgripa urvalet av respondenterna via deras anställd eller deras identitetskortnummer.
Detta nummer måste också väljas slumpmässigt med exempelvis en slumptalsgenerator.

Om studien görs på delar som tillverkats av en maskin måste delarna väljas slumpmässigt, men från satser som tillverkas vid olika tidpunkter på dagen eller på olika dagar eller veckor..
Enkelt slumpmässigt provtagning:
- Det gör det möjligt att minska kostnaderna för en statistisk studie, eftersom det inte är nödvändigt att studera den totala befolkningen för att uppnå statistiskt tillförlitliga resultat, med önskade konfidensnivåer och den felnivå som krävs i studien.
- Undvik partiskhet: eftersom valet av de element som ska studeras är helt slumpmässigt, återspeglar studien troget befolkningens egenskaper, även om endast en del av den studerades.
- Metoden är inte tillräcklig i de fall där du vill veta preferenser i olika grupper eller befolkningsstrat.
I detta fall är det föredraget att tidigare bestämma de grupper eller segment som studien ska utföras på. När skikten eller grupperna har definierats, om det är lämpligt att tillämpa slumpmässigt urval på var och en av dem..
- Det är mycket osannolikt att information kommer att erhållas om minoritetssektorer, av vilka det ibland är nödvändigt att känna till deras egenskaper.
Om det till exempel handlar om att göra en kampanj på en dyr produkt, är det nödvändigt att känna till de rikaste minoritetssektorernas preferenser.
Vi vill studera befolkningens preferens för en viss coladryck, men det finns ingen tidigare studie i denna population, vars storlek är okänd..
Å andra sidan måste provet vara representativt med en lägsta konfidensnivå på 90% och slutsatserna måste ha ett procentuellt fel på 2%..
-Hur man bestämmer provstorleken n?
-Vad skulle urvalsstorleken vara om felmarginalen minskas till 5%??
Eftersom populationsstorleken är okänd används formeln ovan för att bestämma provstorleken:
n = (Ztvåp q) / (Etvå)
Vi antar att det finns lika sannolikhet för preferens (p) för vårt läskedryck som för icke-preferens (q), då är p = q = 0,5.
Å andra sidan, eftersom resultatet av studien måste ha ett procentfel som är mindre än 2%, blir det relativa felet E 0,02.
Slutligen ger ett Z-värde = 1645 en konfidensnivå på 90%.
Sammanfattningsvis har vi följande värden:
Z = 1 645
p = 0,5
q = 0,5
E = 0,02
Med dessa data beräknas minsta provstorlek:
n = (1 645två 0,5 0,5) / (0,02två) = 1691,3
Detta innebär att studien med den nödvändiga felmarginalen och med den valda nivån på förtroende måste ha ett urval av respondenter på minst 1692 individer, valda genom enkel slumpmässig sampling..
Om du går från en felmarginal på 2% till 5% är den nya provstorleken:
n = (1 645två 0,5 0,5) / (0,05två) = 271
Vilket är ett betydligt lägre antal individer. Sammanfattningsvis är provstorleken mycket känslig för önskad felmarginal i studien..


Ingen har kommenterat den här artikeln än.