A empirisk regel Det är resultatet av praktisk erfarenhet och verklighetsobservation. Det är till exempel möjligt att veta vilka fåglar som kan observeras på vissa platser vid varje tid på året och från den observationen kan en "regel" fastställas som beskriver livscyklerna för dessa fåglar.
I statistiken hänvisar den empiriska regeln till hur observationer grupperas kring ett centralt värde, medelvärdet eller genomsnittet, i enheter av standardavvikelse..

Anta att du har en grupp människor med en genomsnittlig höjd på 1,62 meter och en standardavvikelse på 0,25 meter, då skulle den empiriska regeln göra det möjligt för dig att definiera, till exempel, hur många människor som skulle vara i ett intervall av medelvärdet plus eller minus en standardavvikelse?
Enligt regeln är 68% av uppgifterna mer eller mindre en standardavvikelse från medelvärdet, det vill säga 68% av människorna i gruppen kommer att ha en höjd mellan 1,37 (1,62-0,25) och 1,87 (1,62 + 0,25) meter.
Artikelindex
Den empiriska regeln är en generalisering av Tchebyshev-satsen och normalfördelningen.
Tchebyshevs sats säger att: för något värde av k> 1 är sannolikheten att en slumpmässig variabel faller mellan medelvärdet minus k gånger standardavvikelsen och medelvärdet plus k gånger, är standardavvikelsen större än eller lika med (1 - 1 / ktvå).
Fördelen med denna teorem är att den gäller diskreta eller kontinuerliga slumpmässiga variabler med vilken sannolikhetsfördelning som helst, men regeln som definieras från den är inte alltid så exakt, eftersom den beror på fördelningens symmetri. Ju mer sned fördelningen av den slumpmässiga variabeln är, desto mindre anpassad till regeln blir dess beteende.
Den empiriska regel som definieras från denna teorem är:
Om k = √2 sägs det att 50% av data ligger i intervallet: [µ - √2 s, µ + √2 s]
Om k = 2 sägs att 75% av data ligger i intervallet: [µ - 2 s, µ + 2 s]
Om k = 3 sägs att 89% av data ligger i intervallet: [µ - 3 s, µ + 3 s]
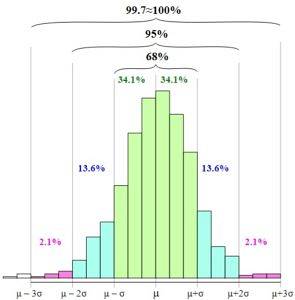
Normalfördelningen, eller Gauss-klockan, gör det möjligt att fastställa den empiriska regeln eller regel 68 - 95 - 99,7.
Regeln baseras på sannolikheten för förekomst av en slumpmässig variabel i intervall mellan medelvärdet minus en, två eller tre standardavvikelser och medelvärdet plus en, två eller tre standardavvikelser..
Den empiriska regeln definierar följande intervall:
68,27% av uppgifterna ligger i intervallet: [µ - s, µ + s]
95,45% av uppgifterna ligger i intervallet: [µ - 2s, µ + 2s]
99,73% av uppgifterna ligger i intervallet: [µ - 3s, µ + 3s]
I figuren kan du se hur dessa intervall presenteras och förhållandet mellan dem när du ökar bredden på grafens bas.
Därför definierar tillämpningen av den empiriska regeln i skala av en normal normalvariabel, z, följande intervall:
68,27% av uppgifterna ligger i intervallet: [-1, 1]
95,45% av uppgifterna ligger i intervallet: [-2, 2]
99,73% av uppgifterna ligger i intervallet: [-3, 3]
Den empiriska regeln tillåter förkortade beräkningar när man arbetar med en normalfördelning.
Antag att en grupp på 100 högskolestudenter har en medelålder på 23 år, med en standardavvikelse på 2 år. Vilken information tillåter den empiriska regeln?
Tillämpningen av den empiriska regeln innebär följande steg:
Eftersom medelvärdet är 23 och standardavvikelsen är 2, är intervallen:
[µ - s, µ + s] = [23 - 2, 23 + 2] = [21, 25]
[µ - 2s, µ + 2s] = [23 - 2 (2), 23 + 2 (2)] = [19, 27]
[µ - 3s, µ + 3s] = [23 - 3 (2), 23 + 3 (2)] = [17, 29]
(100) * 68,27% = 68 studenter ungefär
(100) * 95,45% = 95 studenter ungefär
(100) * 99,73% = cirka 100 studenter
Minst 68 studenter är mellan 21 och 25 år.
Minst 95 studenter är mellan 19 och 27 år.
Nästan 100 studenter är mellan 17 och 29 år.
Den empiriska regeln är ett snabbt och praktiskt sätt att analysera statistiska data, bli mer och mer tillförlitliga när distributionen närmar sig symmetri.
Dess användbarhet beror på vilket område det används och de frågor som presenteras. Det är mycket användbart att veta att förekomsten av värden för tre standardavvikelser under eller över genomsnittet är nästan osannolikt, även för icke-normala fördelningsvariabler, är minst 88,8% av fallen i intervallet tre sigma.
I samhällsvetenskapen är ett generellt avgörande resultat intervallet för medelvärdet plus eller minus två sigma (95%), medan i partikelfysik kräver en ny effekt ett fem sigma-intervall (99,99994%) för att betraktas som en upptäckt..
I ett naturreservat beräknas det finnas i genomsnitt 16 000 kaniner med en standardavvikelse på 500 kaniner. Om fördelningen av variabeln "antal kaniner i reserven" är okänd, är det möjligt att uppskatta sannolikheten för att kaninpopulationen är mellan 15 000 och 17 000 kaniner?
Intervallet kan presenteras i dessa termer:
15000 = 16000 - 1000 = 16000 - 2 (500) = µ - 2 s
17000 = 16000 + 1000 = 16000 + 2 (500) = µ + 2 s
Därför: [15000, 17000] = [µ - 2 s, µ + 2 s]
Genom att tillämpa Tchebyshevs sats finns det en sannolikhet på minst 0,75 att kaninpopulationen i naturreservatet är mellan 15 000 och 17 000 kaniner..
Genomsnittsvikten för ettåriga barn i ett land fördelas normalt med ett medelvärde på 10 kg och en standardavvikelse på cirka 1 kg.
a) Beräkna andelen ettåriga barn i landet som har en genomsnittlig vikt mellan 8 och 12 kg.
8 = 10 - 2 = 10 - 2 (1) = µ - 2 s
12 = 10 + 2 = 10 + 2 (1) = µ + 2 s
Därför: [8, 12] = [µ - 2s, µ + 2s]
Enligt den empiriska regeln kan det konstateras att 68,27% av ettåriga barn i landet har mellan 8 och 12 kg vikt.
b) Vad är sannolikheten för att hitta ett ettårigt barn som väger 7 kg eller mindre?
7 = 10 - 3 = 10 - 3 (1) = ^ - 3 s
Det är känt att 7 kg vikt representerar värdet µ - 3s, liksom det är känt att 99,73% av barnen är mellan 7 och 13 kg vikt. Det lämnar endast 0,27% av de totala barnen i extremiteterna. Hälften av dem, 0,135%, är 7 kg eller mindre och den andra hälften, 0,135%, är 11 kg eller mer.
Så man kan dra slutsatsen att det finns en sannolikhet på 0,00135 att ett barn väger 7 kg eller mindre.
c) Om landets befolkning når 50 miljoner invånare och 1-åriga barn representerar 1% av landets befolkning, hur många ettåriga barn kommer att väga mellan 9 och 11 kg?
9 = 10 - 1 = p - s
11 = 10 + 1 = ^ + s
Därför: [9, 11] = [µ - s, µ + s]
Enligt den empiriska regeln befinner sig 68,27% av ettåringarna i landet i intervallet [µ - s, µ + s]
Det finns 500 000 ettåringar i landet (1% av 50 miljoner), så 341 350 barn (68,27% av 500 000) väger mellan 9 och 11 kg.


Ingen har kommenterat den här artikeln än.