
De trendmått central de anger värdet kring vilket data för en distribution är. Det mest kända är det genomsnittliga eller aritmetiska medelvärdet, som består av att lägga till alla värden och dela resultatet med det totala antalet data.
Men om distributionen består av ett stort antal värden och de inte presenteras på ett ordnat sätt är det inte lätt att utföra de nödvändiga beräkningarna för att extrahera den värdefulla informationen de innehåller..

Det är därför de är grupperade i klasser eller kategorier för att utveckla en distribution av frekvenser. Genom att utföra denna tidigare beställning av data är det lättare att beräkna måtten på den centrala tendensen, bland annat:
-Halv
-Median
-mode
-Geometriskt medelvärde
-Harmoniskt medelvärde
Här är formlerna för måtten på den centrala tendensen för de grupperade data:
Medlet är det mest använda för att karakterisera kvantitativa data (numeriska värden), även om det är ganska känsligt för distributionens extrema värden. Det beräknas av:
Med:
-X: medelvärde eller aritmetiskt medelvärde
-Fi: klassfrekvens
-mi: klassmärket
-g: antal klasser
-n: totala data
För att beräkna det är det nödvändigt att hitta intervallet som innehåller observationen n / 2 och interpolera för att bestämma det numeriska värdet för nämnda observation med hjälp av följande formel:
Var:
-c: bredden på det intervall som medianen tillhör
-BM: nedre gräns för nämnda intervall
-Fm: antal observationer som ingår i intervallet
-n / 2: totala data dividerat med 2.
-FBM: antal observationer innan av intervallet som innehåller medianen.
Därför är medianen ett mått på position, det vill säga det delar upp datamängden i två delar. De kan också definieras kvartiler, deciler Y percentiler, som delar fördelningen i fyra, tio respektive hundra delar.
I de samlade uppgifterna söks den klass eller kategori som innehåller flest observationer. Det här är modal klass. En distribution kan ha två eller flera lägen, i vilket fall den kallas bimodal Y multimodal, respektive.
Du kan också beräkna läget i grupperade data enligt ekvationen:
Med:
-L1: nedre gräns för klassen där läget finns
-Δ1: subtrahera mellan modalklassens frekvens och frekvensen för den klass som föregår den.
-Δtvå: subtrahera mellan modalklassens frekvens och frekvensen för nästa klass.
-c: bredden på intervallet som innehåller läget
Det harmoniska medelvärdet betecknas med H. När du har en uppsättning n x-värden1, xtvå, x3..., Det harmoniska medelvärdet är det omvända eller ömsesidiga av det aritmetiska medelvärdet av de inversa värdena.
Det är lättare att se det genom formeln:
Och med den grupperade informationen tillgänglig blir uttrycket:
Var:
-H: harmoniskt medelvärde
-Fi: klassfrekvens
-mi: klassmärke
-g: antal klasser
-N = f1 + Ftvå + F3 +...
Om de har n positiva tal x1, xtvå, x3…, Dess geometriska medelvärde G beräknas av produktens n: te rot av alla siffror:
När det gäller grupperade data kan det visas att decimallogaritmen för den geometriska medelloggen G ges av:
Var:
-G: geometriskt medelvärde
-Fi: klassfrekvens
-mi: klassmärket
-g: antal klasser
-N = f1 + Ftvå + F3 +...
Det är alltid sant att:
H ≤ G ≤ X
Följande definitioner krävs för att hitta värdena som beskrivs i formlerna ovan:
Frekvens definieras som antalet gånger en bit data upprepas.
Det är skillnaden mellan de högsta och lägsta värdena som finns i fördelningen.
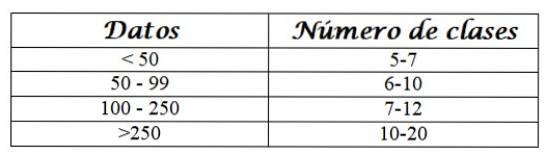
För att veta i hur många klasser vi grupperar data använder vi några kriterier, till exempel följande:
De extrema värdena för varje klass eller intervall kallas gränser och varje klass kan ha båda väldefinierade gränser, i vilket fall den har en lägre och en högre gräns. Eller så kan det ha öppna gränser när ett intervall anges, till exempel värden som är större eller mindre än ett visst antal.
Den består helt enkelt av mittpunkten för intervallet och beräknas genom medelvärdet av den övre och undre gränsen.
Data kan grupperas i klasser av lika eller olika storlek, detta är bredden eller bredden. Det första alternativet är det mest använda, eftersom det gör beräkningar mycket enklare, även om det i vissa fall är absolut nödvändigt att klasserna har olika bredd.
Bredden c Intervallet kan bestämmas med följande formel:
c = Räckvidd / Nc
Varc är antalet klasser.
Nedan har vi en serie hastighetsmätningar i km / h, tagna med radar, som motsvarar 50 bilar som passerade genom en gata i en viss stad:
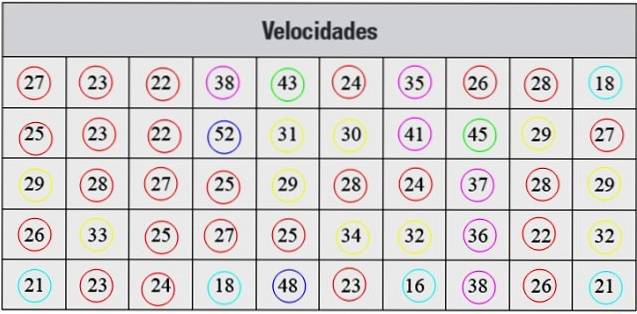
De data som presenteras på detta sätt är inte organiserade, så det första steget är att gruppera dem i klasser.
Hitta intervallet R:
R = (52 - 16) km / h = 36 km / h
Välj antal klasser Nc, enligt givna kriterier. Eftersom det finns 50 data kan vi välja Nc = 6.
Beräkna bredd c av intervallet:
c = Område / N.c = 36/6 = 6
Formklasser och gruppdata enligt följande: för den första klassen väljs ett värde som är något mindre än det lägsta värdet i tabellen som den undre gränsen, sedan läggs värdet på c = 6, tidigare beräknat, till detta värde, alltså uppnår den första klassens övre gräns.
Vi fortsätter på samma sätt för att bygga resten av klasserna, som visas i följande tabell:
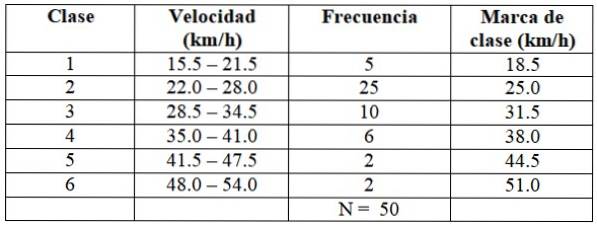
Varje frekvens motsvarar en färg i figur 2, på detta sätt säkerställs att inget värde slipper räknas..
X = (5 x 18,5 +25 x 25,0 + 10 x 31,5 + 6 x 38,0 + 2 x 44,5 + 2 x 51,0) ÷ 50 = 29,03 km / h
Medianen är i klass 2 i tabellen, eftersom det finns de första 30 data för distributionen.
-Bredden på det intervall som medianen tillhör: c = 6
-Nedre gräns för intervallet där medianen är: BM = 22,0 km / h
-Antal observationer som intervallet f innehållerm = 25
-Totala data dividerat med 2: 50/2 = 25
-Antal observationer som finns innan av intervallet som innehåller medianen: fBM = 5
Och operationen är:
Median = 22,0 + [(25-5) ÷ 25] × 6 = 26,80 km / h
Mode är också i klass 2:
-Intervallbredd: c = 6
-Nedre gräns för klassen där läget finns: L1 = 22,0
-Subtrahera mellan modalklassens frekvens och frekvensen för den klass som föregår den: Δ1 = 25-5 = 20
-Subtrahera mellan modalklassens frekvens och frekvensen för klassen som följer: Δtvå = 25 - 10 = 15
Med dessa data är operationen:
Läge = 22,0 + [20 ÷ (20 + 15)] x6 = 25,4 km / h
N = f1 + Ftvå + F3 +... = 50
logg = (5 x log 18,5 + 25 x log 25 + 10 x log 31,5 + 6 x log 38 + 2 × log 44,5 + 2 x log 51) / 50 =
logg G = 1,44916053
G = 28,13 km / h
1 / H = (1/50) x [(5 / 18,5) + (25/25) + (10 / 31,5) + (6/38) + (2 / 44,5) + (2/51)] = 0,0366
H = 27,32 km / h
Enheterna för variablerna är km / h:
-Genomsnitt: 29.03
-Median: 26.80
-Mode: 25.40
-Geometriskt medelvärde: 28,13
-Harmoniskt medelvärde: 27,32



Ingen har kommenterat den här artikeln än.